

寫得太整齊,反而被懷疑?論 AI 時代的職場身份困境
前言
說實在的,這篇文章本身就是個反諷。你等一下讀完,如果覺得它寫得太整齊、太有條理,請不要懷疑,這是人寫的。我已經被 AI 說過一次了,不想再來一次。
我們花了幾十年被教導:把事情說清楚、邏輯要有條理、格式要整齊。這些本來是一個專業工作者應有的基本素養。但現在出現了一件很荒謬的事,當你真的做到了,AI 偵測工具反而說這不像人寫的。
這篇文章要談的,不是 AI 有多厲害,而是在 AI 全面進入職場的今天,「邏輯清晰、格式嚴謹」這件事,正在製造一種新的困境。對於那些長期追求高品質輸出的工作者來說,這困境是一個需要認真面對的管理與職場議題。

社會現象觀察:我寫得太好了,所以被懷疑了?
我有一個習慣,寫東西一定要格式整齊、結構清楚、邏輯前後連貫。這不是強迫症(好啦,也許有一點),而是多年下來對自己的基本要求。一份沒有條理的文件,連我自己都過不了關。
前一陣子,我把自己寫的一篇文章丟進某一平台,想說讓 AI 給點意見。結果 AI 跟我說,這篇文章「太整齊了」,看起來像是 AI 生成的。我盯著螢幕看了幾秒鐘,以為自己看錯了。我又試了 另一個平台。
一樣。
這篇文章是我自己寫的,每一個字都是我自己打的,每一個論點都是我自己思考過的,有些段落我還改了三四遍才滿意。但 AI 告訴我,我寫的東西不像人寫的。那一刻我有點想笑,但笑不太出來,因為我突然意識到一件事:如果連我自己都沒辦法證明這是我寫的,那其他人呢?那些在職場上認真做事、認真輸出的人呢?
老實說,這個問題讓我想了很久。在 AI 大量生產內容的今天,一個長期要求自己輸出品質的工作者,要怎麼證明自己的內容是真實的?當「寫得好」開始成為一種嫌疑,這個職場的評估邏輯,是不是出了什麼問題?

企業營運影響分析:當高品質輸出變成組織風險,誰還願意認真?
我的遭遇,聽起來像是個人的尷尬小插曲。但這件事之所以值得認真討論,是因為同樣的邏輯,正在以更有組織、更有規模的方式,進入企業的人才評估制度裡。
說白了就是這樣:我是自己把文章丟進去測試,結果很荒謬,但沒有人因此評判我的工作表現。可是現在,有愈來愈多企業的 HR 部門,開始把 AI 偵測工具引進到正式的審查流程裡,用來掃描員工的報告、提案、甚至績效自評。這一步的距離,從「我自己玩玩」到「公司拿來評斷你」,才是真正讓問題變嚴重的地方。
這套邏輯有一個根本的缺陷:它把「看起來像 AI」和「就是 AI 寫的」畫上了等號。一個長期要求自己邏輯嚴謹、格式整齊的資深工作者,在這套系統眼中,反而成了高風險對象。問題不在於 AI 偵測工具存不存在,而在於組織有沒有意識到,這套工具的判斷基準,從一開始就帶著結構性的偏差。
這對組織帶來的影響,比表面看起來嚴重。評估工具的判斷出了問題,輸出品質愈高的人,反而愈容易被質疑。主管在看一份報告的時候,腦袋裡多了一個雜音:「這真的是他自己寫的嗎?」這個念頭出現之後,對員工的評價就很難再純粹。
更麻煩的是,當員工發現「寫太好會被懷疑」,有些人會開始刻意調低自己的輸出水準,讓內容看起來更「有人味」。(這部分主管通常不會發現,因為標準降低是漸進的,不是某天突然變差。)這不是個人選擇的問題,而是一種組織氛圍在無聲地引導行為。
一個長期被懷疑的人,難以持續保持高度投入;一個獎勵「看起來像人寫的」而非「真正高品質」的組織,知識水準只會悄悄往下走,沒有人察覺,直到某天開始感覺哪裡不對勁。
更深層的問題在於,許多組織對於「如何在 AI 時代重新定義人才的輸出標準」,根本還沒有準備好。
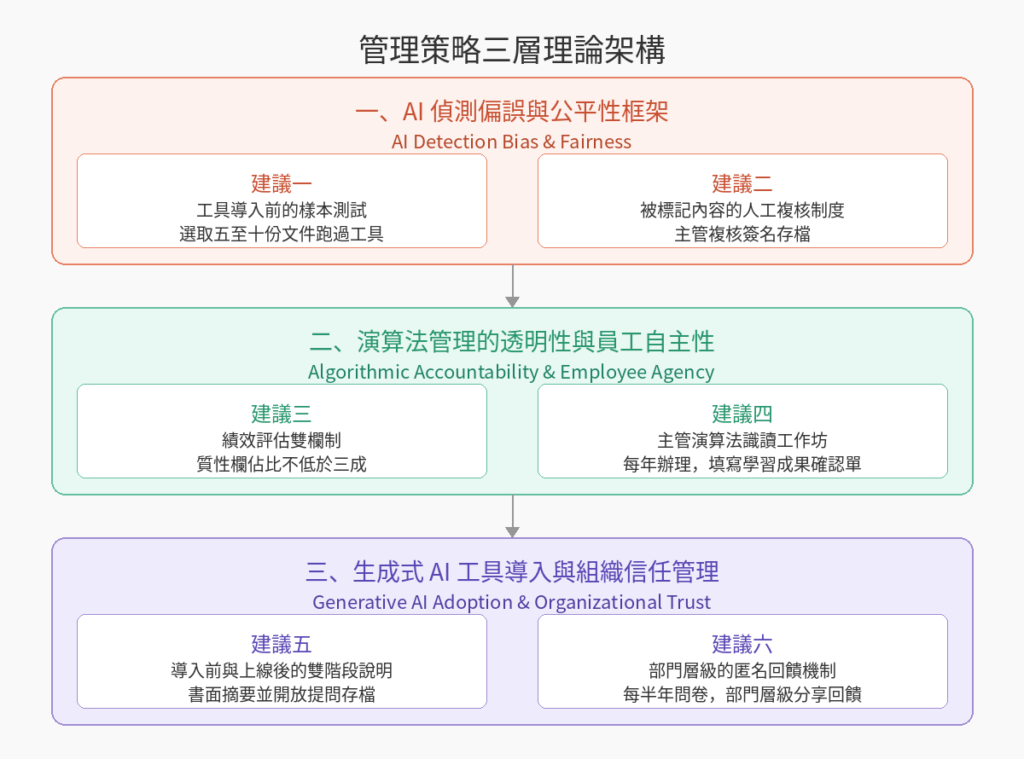
管理策略與理論應用:看清工具邊界,組織如何重建失落的信任?
這個問題的核心不是技術問題,而是管理問題。AI 偵測工具的判斷邏輯,來自於它被訓練的方式,而不是來自於對「人」的真正理解。當組織把這套工具的輸出結果直接當成評估員工的依據,問題就從工具層面升級成了制度層面。以下為相關理論與組織可應用的分析。
(一)AI 偵測偏誤與公平性框架(AI Detection Bias & Fairness)
我先說一個數字,再說它的限制。史丹佛大學的研究團隊 Liang 等人(2023)做了一個測試,把七種主流 AI 偵測工具拿來判斷非英語母語者寫的文章,其中一種工具的誤判率高達 98%。這個數字是在特定測試條件下、針對特定工具的結果,不代表所有偵測工具的普遍表現,放大解讀會失準。但它揭示了一件真實存在的事:這類工具的判斷邏輯,對結構嚴謹、用詞精準的寫作風格本來就存在系統性的偏差,不是偶發的,是設計上就帶進來的。
對 HR 主管來說,這個研究指向的是制度設計的責任,不只是技術選型的問題。以下是兩個可以立即落地的做法:
1.「工具導入前的樣本測試」:在採購任何 AI 偵測工具前,由 HR 指定一名人員,從現有員工文件中選取五至十份已確認為本人撰寫的高品質報告,在正式上線前先跑過工具,記錄誤判比例。若誤判率超過兩成,暫緩導入並要求供應商說明。這不是在刁難供應商,是在確認這個工具能不能用在你的人身上,而不只是在簡報上看起來很厲害。
2.「被標記內容的人工複核制度」:任何被 AI 工具標記為可疑的內容,一律由直屬主管進行複核,複核採結構化勾選表單,主管須就「內容是否符合當事人的工作知識」與「是否與過往表現一致」兩個面向作出判斷,並簽名存檔。HR 統一制定表單格式,確保複核有據可查,不讓工具的判斷直接影響員工的評估結果。
(二)演算法管理的透明性與員工自主性(Algorithmic Accountability & Employee Agency)
Konjen(2025,arXiv 預印本,尚未經同儕審查期刊正式收錄)的研究指出,演算法管理系統傾向於把人的工作簡化成可量化的指標,忽略那些無法被數字捕捉的能力,包括創意、協作、在複雜情境下的細膩判斷。這在台灣職場裡特別有感,因為很多真正重要的事根本不在系統裡,例如那個每次跨部門卡關都能把事情喬好的人,或者那個新人問問題永遠有耐心解釋的資深同事,這些貢獻從來不會出現在任何報表裡,但組織少了這些人會立刻感覺到。
解法不是廢掉工具,而是在制度設計上重新確立「人的判斷」的位置。以下兩個做法能幫助組織在效率與公平之間找到平衡:
1.「績效評估雙欄制」:在現行績效評估表單中,劃分量化欄與質性欄兩個區塊,量化欄記錄系統產生的數據,質性欄由主管填寫無法量化的貢獻,例如跨部門協作、非正式知識傳授、危機判斷品質。質性欄佔整體評估比例不低於三成,並事先向員工公開說明。只需修改現行表單,不需動系統,是落地成本最低的一個做法。
2.「主管演算法識讀工作坊」:每年辦理一次,內容聚焦在現行工具的判斷原理、已知侷限,以及哪些情境下不應依賴系統輸出。課程結束後填寫「學習成果確認單」,取代追責式的責任書,讓主管在理解工具邊界的前提下做判斷,而不是把工具結果當成免責的擋箭牌。
(三)生成式 AI 工具導入與組織信任管理(Generative AI Adoption & Organizational Trust)
信任這件事,比大多數主管想的更難修復。Gkinko 與 Elbanna(2023)的研究發現,員工對組織導入 AI 工具的信任,不只取決於工具本身好不好用,更取決於組織在導入過程中的態度,包括有沒有說清楚這套工具在做什麼、有沒有讓員工覺得自己被當成人在對待,而不只是被系統管理的一個資料點。
組織建立信任的方式,不是叫員工「相信系統」,而是讓員工「看見組織的態度」。以下兩個做法能幫助組織在 AI 工具導入過程中主動守住信任的基礎:
1.「導入前與上線後的雙階段說明」:工具正式上線前,由 HR 主管召開說明會,說明工具用途、能判斷什麼、不能判斷什麼,以及何種情況下會啟動人工複核。上線後三個月再辦一次追蹤說明,讓員工確認實際運作是否與當初承諾一致。兩個階段都提供書面摘要並開放提問,問題與回應一併存檔。這兩個動作加起來不超過半天,但它們能讓員工感覺到,組織不是拿工具來對付他們。
2.「部門層級的匿名回饋機制」:每半年透過匿名問卷收集員工對 AI 工具使用的感受,回饋結果在部門層級分享,主管須說明根據回饋採取了哪些具體調整。先從部門開始,讓管理者有能力消化並回應,不承諾全員公開,避免問卷發出後沒有下文,反而比不發問卷更傷信任。
結論
寫到這裡,我突然想再把這篇文章丟進AI平台測一次。但算了,我已經知道結果了。我們花了幾十年把自己訓練成一個邏輯清楚、格式嚴謹的人,然後有一天機器跑來告訴我們,這樣不夠像人。問題不在我們身上,在於那些還沒搞清楚工具邊界就拿去評斷人的組織。搞懂它能做什麼、不能做什麼,讓它回到工具該待的位置,而不是反過來讓人去配合工具想看到的樣子。只是大多數組織,連這個問題都還沒意識到自己有。

參考文獻
Gkinko, L., & Elbanna, A. (2023). Designing trust: The formation of employees’ trust in conversational AI in the digital workplace. Journal of Business Research, 158, Article 113707. https://doi.org/10.1016/j.jbusres.2023.113707
Konjen, H. (2025). Algorithmic management and the future of human work: Implications for autonomy, collaboration, and innovation [Preprint]. arXiv. https://arxiv.org/abs/2511.14231
Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7), Article 100779. https://doi.org/10.1016/j.patter.2023.100779


